
Maciej Miszczyk
Fuzzowanie programem AFL na przykładzie biblioteki GuruxDLMS.c
Fuzzowanie – technika poszukiwania błędów bezpieczeństwa
Fuzzowanie (fuzzing, fuzz testing) jest jedną z najpopularniejszych technik poszukiwania błędów bezpieczeństwa, w szczególności tych związanych z dostępem do pamięci (np. buffer overflow, use after free). Błędy tego rodzaju są potencjalnie najniebezpieczniejszymi błędami w programach napisanych w językach kompilowanych do kodu maszynowego (np. C i C++), w najgorszym razie umożliwiając atakującemu zdalne przejęcie kontroli nad podatnym na nie programem.

Fuzzing – zasada działania
Zasada działania fuzzingu jest prosta: do badanego programu dostarczamy losowo wygenerowane dane wejściowe szukając takich, które spowodują jego niepoprawne zatrzymanie (w systemach unixopodobnych najczęściej poprzez sygnał SEGV wysyłany przez system operacyjny w momencie, kiedy program próbuje w niepoprawny sposób dostać się do chronionej pamięci – np. przez wpisanie danych w obszary oznaczone jako tylko do odczytu). Jednak nowoczesne, inteligentne fuzzery są czymś więcej niż tylko generatorami liczb losowych: starają się one uzyskać jak największe pokrycie kodu dzięki zastosowaniu instrumentacji (sprawia ona, że badany program informuje fuzzer o tym które miejsca w kodzie zostały odwiedzone podczas przetwarzania wygenerowanych danych) i algorytmu genetycznego (dzięki któremu nowe dane będą bardziej podobne do tych, które odkryły wcześniej niezbadane miejsca w kodzie).
W tym artykule zaprezentujemy przykład zastosowania inteligentnego fuzzera AFL do znajdowania błędów w open source’owej bibliotece GuruxDLMS.c. Badana biblioteka jest implementacją protokołu DLMS wykorzystywanego w branży elektroenrgetycznej do elektronicznego odczytu liczników zużycia energii. W naszym scenariuszu ataku, atakujący próbuje połączyć się z serwerem (licznikiem) korzystającym z biblioteki GuruxDLMS.c celem zakłócenia jego pracy lub przejęcia nad nim kontroli (np. w celu zafałszowania późniejszych odczytów).
W repozytorium biblioteki GuruxDLMS.c znaleźć można katalog GuruxDLMSSimpleServerExample, zawierający przykładową implementację licznika opartego o tę bibliotekę. Jak możemy zaobserwować w funkcji main(), działa on poprzez nasłuchiwanie na porcie TCP 4061 i przesłanie każdego otrzymanego bajtu do funkcji svr_handleRequest3().
#if defined(_WIN32) || defined(_WIN64)//Windows includes
int _tmain(int argc, _TCHAR* argv[])
#else
int main(int argc, char* argv[])
#endif
{
unsigned char data;
struct sockaddr_in client;
int ret, ls, s;
struct sockaddr_in add = { 0 };
#if defined(_WIN32) || defined(_WIN64)//If Windows
int len;
int AddrLen = sizeof(add);
#else //If Linux
socklen_t len;
socklen_t AddrLen = sizeof(add);
#endif
#if defined(_WIN32) || defined(_WIN64)//Windows includes
WSADATA wsaData;
if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0)
{
// Tell the user that we could not find a usable WinSock DLL.
return 1;
}
#endif
bb_init(&reply);
//Start server using logical name referencing and HDLC framing.
svr_init(&settings, 1, DLMS_INTERFACE_TYPE_HDLC, HDLC_BUFFER_SIZE, PDU_BUFFER_SIZE, frame, HDLC_BUFFER_SIZE, pdu, PDU_BUFFER_SIZE);
//Add COSEM objects.
svr_InitObjects(&settings);
//Start server
if ((ret = svr_initialize(&settings)) != 0)
{
//TODO: Show error.
return 1;
}
ls = socket(AF_INET, SOCK_STREAM, 0);
add.sin_port = htons(4061);
add.sin_addr.s_addr = htonl(INADDR_ANY);
add.sin_family = AF_INET;
if ((ret = bind(ls, (struct sockaddr*) &add, sizeof(add))) == -1)
{
return -1;
}
while (1)
{
if ((ret = listen(ls, 1)) == -1)
{
//socket listen failed.
return -1;
}
len = sizeof(client);
s = accept(ls, (struct sockaddr*)&client, &len);
while (1)
{
//Read one char at the time.
if ((ret = recv(s, (char*)&data, 1, 0)) == -1)
{
#if defined(_WIN32) || defined(_WIN64)//If Windows
closesocket(s);
s = INVALID_SOCKET;
#else //If Linux
close(s);
s = -1;
#endif
break;
}
//If client closes the connection.
if (ret == 0)
{
#if defined(_WIN32) || defined(_WIN64)//If Windows
closesocket(s);
s = INVALID_SOCKET;
#else //If Linux
close(s);
s = -1;
#endif
break;
}
if (svr_handleRequest3(&settings, data, &reply) != 0)
{
#if defined(_WIN32) || defined(_WIN64)//If Windows
closesocket(s);
s = INVALID_SOCKET;
#else //If Linux
close(s);
s = -1;
#endif
break;
}
if (reply.size != 0)
{
if (send(s, (const char*)reply.data, reply.size – reply.position, 0) == -1)
{
#if defined(_WIN32) || defined(_WIN64)//If Windows
closesocket(s);
s = INVALID_SOCKET;
#else //If Linux
close(s);
s = -1;
#endif
break;
}
bb_clear(&reply);
}
}
}
#if defined(_WIN32) || defined(_WIN64)//Windows
WSACleanup();
#if _MSC_VER > 1400
_CrtDumpMemoryLeaks();
#endif
#endif
return 0;
}
Domyślnie AFL działa przekazując badanemu programowi dane wejściowe przekazując mu jako argument nazwę wygenerowanego pliku. Musimy więc przepisać przykładową aplikację żeby zamiast słuchać na porcie TCP, otwierała i czytała plik do którego ścieżka przekazana będzie w argv[1]. Pozostała logika pozostanie bez zmian: każdy bajt pliku po kolei przekazywać będziemy do istniejącej już funkcji svr_handleRequest3() – w ten sposób mamy pewność, że jedyną zmianą w stosunku do przykładowego serwera jest sposób przyjmowania danych wejściowych.
// GuruxDLMSSimpleServerExample/src/main.c
int main(int argc, char **argv){
unsigned char data;
FILE *f;
if(argc < 2){
puts(“Error. Please provide a filename”);
return 1;
}
svr_init(&settings, 1, DLMS_INTERFACE_TYPE_HDLC, HDLC_BUFFER_SIZE,
PDU_BUFFER_SIZE, frame, HDLC_BUFFER_SIZE, pdu, PDU_BUFFER_SIZE);
svr_InitObjects(&settings);
if(svr_initialize(&settings)){
puts(“Server init error”);
return 2;
}
if(!(f = fopen(argv[1], “rb”))){
puts(“Error reading file”);
return 3;
}
while(fread(&data, sizeof(unsigned char), 1, f)){
if(svr_handleRequest3(&settings, data, &reply)){
puts(“Error when handling request”);
break;
}
if(reply.size != 0){
printf(“Server reply: %s\n”, reply.data);
bb_clear(&reply);
}
}
puts(“EOF”);
fclose(f);
return 0;
}
Tak przygotowany program możemy skompilować z instrumentacją AFL. Dla ułatwienia analizy błędów możemy zastosować też program ASAN (Address Sanitizer) który zatrzyma program od razu po wykryciu niepoprawnego dostępu do pamięci i poinformuje nas zarówno o miejscu w kodzie w którym taki dostęp miał miejsce, jak i o miejscu w którym pamięć została zaalokowana.
Kompilacja z AFL i ASAN wymaga modyfikacji plików development/makefile i GuruxDLMSSimpleServerExample/makefile. Musimy zmienić w nich kompilator (zmienna CC) z domyślnego gcc na afl-clang. Do zmiennych CFLAGS i LFLAGS musimy w obu plikach dodać flagę -fsanitize=address. Po wprowadzeniu tych zmian, wykonujemy następujące polecenia:
cd development
make
cp lib/libgurux_dlms_c.a ../GuruxDLMSSimpleServerExample/obj/
cd ../GuruxDLMSSimpleServerExample
make
Skompilowany program znajduje się w lokacji GuruxDLMSSimpleServerExample/bin/gurux.dlms.simple.server.bin. Dla poprawnego działania fuzzera brakuje nam jeszcze tylko katalogów input i output. Utworzymy je następującymi poleceniami:
mkdir input
mkdir output
O ile zawartość drugiego katalogu zostanie utworzona w wyniku działania AFLa, w pierwszym powinny znaleźć się przykładowe poprawne dane wejściowe na podstawie których fuzzer będzie tworzył potencjalnie niebezpieczne pliki. Co jednak możemy zrobić jeśli nie mamy takich danych? Musimy po prostu uzbroić się w cierpliwość: dzięki algorytmowi genetycznemu, AFL prędzej czy później zacznie generować poprawną komunikację DLMS nawet jeżeli początkowymi danymi będzie, na przykład, pojedyncza spacja.
echo ‘ ‘ > input/1
W tym momencie, mamy już wszystko co potrzebne do rozpoczęcia fuzzowania. Pracę AFLa rozpocząć możemy taką komendą:
afl-fuzz -i input/ -o output/ bin/gurux.dlms.simple.server.bin @@
Co oznacza tajemniczy ciąg znaków „@@”? To po prostu oznaczenie miejsca, w które fuzzer podstawi ścieżkę do wygenerowanego pliku. Dlaczego musimy tak robić? Należy pamiętać, że nie w każdym programie ścieżkę do pliku przekazywać będziemy w argv[1]. Czasami potrzebne będzie użycie flagi, np. –input-file @@.
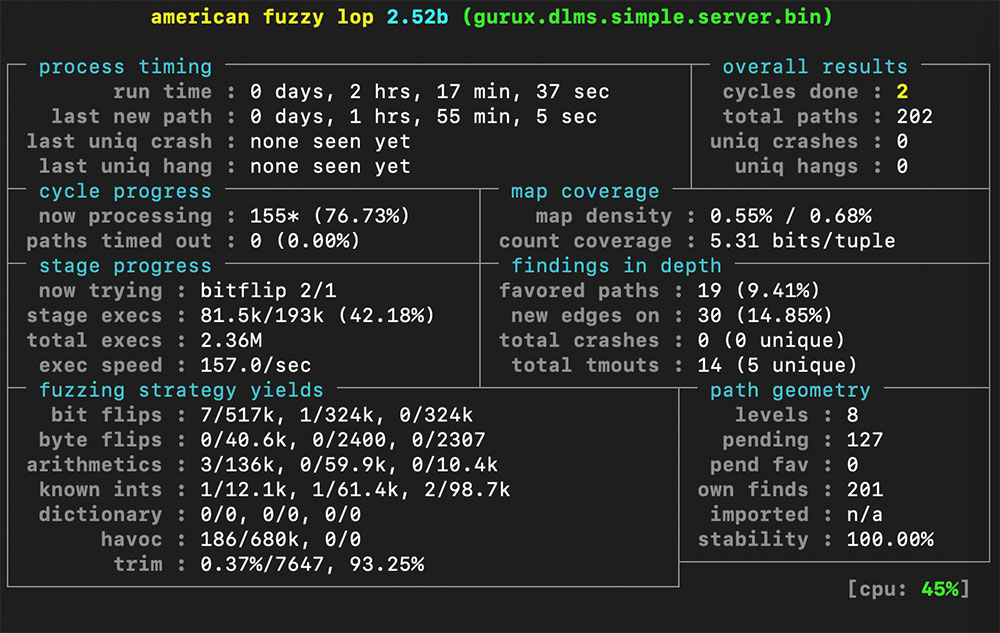
Po paru godzinach działania fuzzera, możemy zaobserwować że jego wyniki nie są najlepsze: nie odnajduje on zbyt wielu nowych ścieżek, i ani razu nie udało mu się doprowadzić do przerwania działania programu. Dlaczego? Okazuje się, że protokół DLMS przewiduje weryfikację sum kontrolnych wiadomości. Nawet inteligentne fuzzery korzystające z algorytmów genetycznych nie są jeszcze w stanie policzyć i umieścić w odpowiednim miejscu sumy kontrolnej.
Jednym z rozwiązań tego problemu mogłoby być stworzenie skryptu, który analizuje ramki DLMS i poprawia sumy kontrolne (byłoby to konieczne gdybyśmy chcieli wykorzystać znalezione błędy do prawdziwych ataków). W tym celu można zastosować np. narzędzie AFL post_library służące do przekształcania wygenerowanych plików. My jednak wybierzemy prostsze rozwiązanie: wyłączymy weryfikację sumy kontrolnej w kodzie programu, skompilujemy go ponownie i uruchomimy fuzzer.
// development/src/dlms.c
int dlms_getHdlcData(
unsigned char server,
dlmsSettings * settings,
gxByteBuffer * reply,
gxReplyData * data,
unsigned char* frame,
unsigned char preEstablished,
unsigned char first)
{
//(…)
crc = countCRC(reply, packetStartID + 1,
reply->position – packetStartID – 1);
if ((ret = bb_getUInt16(reply, &crcRead)) != 0)
{
return ret;
}
/* if (crc != crcRead)
{
if (reply->size – reply->position > 8)
{
return dlms_getHdlcData(server, settings, reply, data, frame, preEstablished, first);
}
return DLMS_ERROR_CODE_WRONG_CRC;
}*/
// Check that packet CRC match only if there is a data part.
if (reply->position != packetStartID + frameLen + 1)
{
crc = countCRC(reply, packetStartID + 1, frameLen – 2);
if ((ret = bb_getUInt16ByIndex(reply, packetStartID + frameLen – 1, &crcRead)) != 0)
{
return ret;
}
/* if (crc != crcRead)
{
return DLMS_ERROR_CODE_WRONG_CRC;
}*/
//(…)
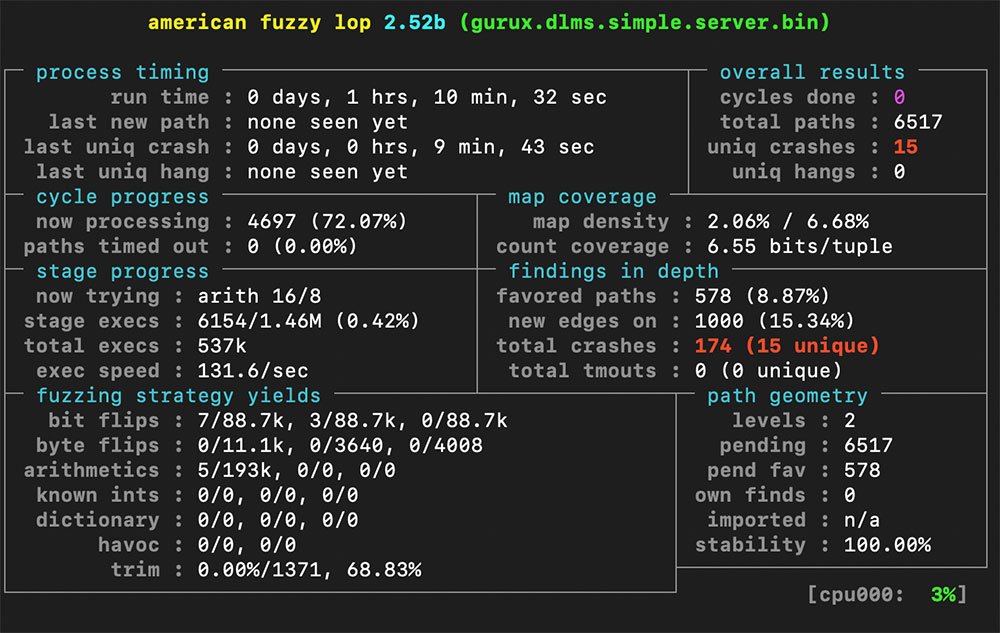
Jak widać, byliśmy w stanie znaleźć pliki powodujące niepoprawne zatrzymanie programu. Zobaczmy jak zachowuje się program kiedy ręcznie przekażemy mu jeden z nich:
==10691==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7fffffffd5c1 at pc 0x7ffff6ee2397 bp 0x7fffffffd510 sp 0x7fffffffccb8
READ of size 8187 at 0x7fffffffd5c1 thread T0
#0 0x7ffff6ee2396 in __asan_memcpy (/usr/lib/x86_64-linux-gnu/libasan.so.4+0xc8396)
#1 0x55555564b551 in ba_copy src/bitarray.c:203
#2 0x55555568d1c7 in apdu_parseProtocolVersion src/apdu.c:1067
#3 0x55555568e864 in apdu_parsePDU src/apdu.c:1428
#4 0x5555556aca38 in svr_HandleAarqRequest src/server.c:325
#5 0x5555556c22a3 in svr_handleCommand src/server.c:2398
#6 0x5555556c494f in svr_handleRequest2 src/server.c:2700
#7 0x5555556c6333 in svr_handleRequest3 src/server.c:2467
#8 0x555555695dff in main src/main.c:479
#9 0x7ffff648db96 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x21b96)
#10 0x5555555603b9 in _start (/home/afl/fuzzer/gurux.dlms.simple.server.bin+0xc319)
Analizując kod źródłowy funkcji pojawiających się na stosie wywołań, możemy szybko odkryć przyczynę błędu: jeżeli (wyczytana z naszego pliku) wartość zmiennej unusedBits jest większa niż 8, następuje błąd typu integer overflow w wyniku którego wartość przekazana do funkcji ba_copy() będzie większa niż rozmiar tablicy z której ta funkcja kopiuje dane. Mamy więc do czynienia z błędem typu out-of-bounds read.
// development/src/apdu.c
int apdu_parseProtocolVersion(dlmsSettings* settings,
gxByteBuffer* buff)
{
//(…)
if ((ret = bb_getUInt8(buff, &unusedBits)) != 0)
{
return ret;
}
//(…)
bitArray bb;
ba_init(&bb);
ba_copy(&bb, &value, 8 – unusedBits);
//(…)
}
Jak poważny jest błąd z którym mamy do czynienia? Nadmiarowe dane skopiowane spoza bufora wydają się nie być nigdzie wysyłane (nie będzie to więc podatność tak poważna jak słynny Heartbleed w bibliotece OpenSSL), jednak nawet w wersji serwera skompilowanej bez instrumentacji ASANa i AFLa możemy zaobserwować, że niektóre wywołania kończą się błędem segmentacji. Oznacza to, że atakujący mógłby wykorzystać znaleziony przez nas błąd do przerwania pracy licznika – a z analizy kodu wywnioskować można, że nawet jeżeli licznik zabezpieczony jest hasłem to podatna funkcja wywoływana jest przed jego sprawdzeniem. Mamy więc do czynienia z nieuwierzytelnionym atakiem typu DoS.
Oczywiście opisana przez nas podatność nie występuje w aktualnych wersjach badanego oprogramowania: zgłosiliśmy ją (wraz z innymi błędami odkrytymi w procesie fuzzingu) do producenta i przed publikacją upewniliśmy się, że została ona naprawiona. Jednak wiele oprogramowania z którego korzystamy na codzień – także oprogramowania działającego na urządzeniach przemysłowych – wciąż może posiadać takie (lub groźniejsze) błędy. Warto też zwrócić uwagę na stan bezpieczeństwa bibliotek które włączamy do swoich programów – a jeżeli (tak jak w przypadku open source’owego oprogramowania firmy Gurux) mamy dostęp do kodu źródłowego, nie zaszkodzi poświęcić trochę czasu i cykli procesora na fuzzowanie.
0 komentarzy